
Namespace, o que é?
Artigo escrito em Dezembro de 2017 no Medium.
Sumário
Muito se fala em containers, e como a maneira de trabalhar com computação mudou. Basta entrar em alguns grupos do Telegram sobre desenvolvimento ou infraestrutura que em pouco tempo, alguém está postando um artigo sobre docker, ou procurando saber algo específico sobre kubernets, etc. O que muita gente não sabe (e isso vem crescendo gradualmente cada vez mais na área de computação, e vou tentar explicar o porquê em uma postagem futura) é como o docker, ou outras tecnologias de containers funcionam internamente no sistema em que estão executando.
Basicamente, um container (independente da tecnologia) é formado por 2 elementos: Cgroups e Namespaces. Resumidamente, o namespace oferece isolamento dos recursos e o cgroups impõe limites de recursos aos ambientes isolados. Claro que isso é uma visão simplificada do que cada coisa é, mas vamos deixar para explorar o Cgroups em uma futura postagem.
Mas, o que é namespace?
Introduzido em 2002, na versão 2.4.19 do kernel Linux, Namespace é uma feature que permite criar e lidar com diversos contextos em um mesmo sistema, vendo propriedades globais diferentes e isoladas em cada contexto. Para facilitar o entendimento, com namespace é possível criar um contexto (ou ambiente) de rede isolado do ambiente físico. Nesse novo contexto, existirão interfaces de rede física que não são visíveis no contexto do sistema; essas interfaces terão endereços físicos e lógicos diferentes do contexto do sistema e todo tráfego, regras de firewall, existentes nesse novo contexto, não são vistos por nenhum outro contexto, incluindo o contexto do sistema.
Essa é a feature que é utilizada para garantir isolamento. Embora exemplifiquei utilizando recursos de rede, existem diversos recursos que podem ser isolados utilizando namespaces. Os principais são:
- Mount (mnt) namespace
- Process identify (pid) namespace
- Unix timesharing system (UTS) namespace
- Network (net)namespace
- inter-process comunication (IPC) namespace
- user namespace
O Mount namespaces é responsável por criar um contexto isolado do sistemas para dispositivos que podem ser montados pelo sistema. Aqui, você pode observar que nem todo dispositivo montado no contexto físico deve ser disponibilizado para containers, ou algo que é montado em um container não deve ser também montado em outro. Precisa existir um isolamento e o mount namespaces garante isso para o recurso de dispositivos montados.
Além desses, existem também artigos que complementam a necessidade de isolar outros recursos encontrados nos sistemas Linux através de namespaces. Eles foram propostos e que ainda não foram implementados, como por exemplo:
- time namespace
- system log (syslog) namespace
Arquitetura de namespaces
A maneira que o sistema operacional irá criar e gerenciar namespaces depende principalmente da arquitetura de namespace que é implementado no kernel do sistema operacional. Existem duas arquiteturas básicas que os namespaces podem ser implementados: a arquitetura hierárquica e a não-hierárquica.
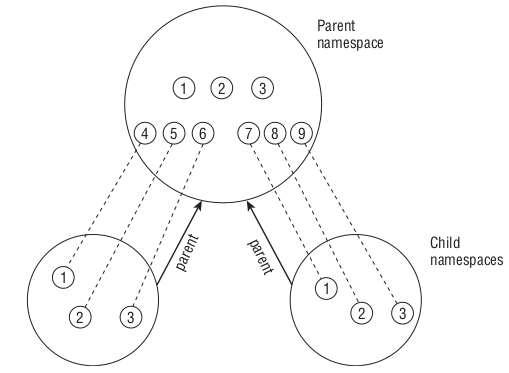
A arquitetura hierárquica relaciona os recursos em diferentes contextos. Geralmente os recursos dos novos contextos são relacionados com o contexto do sistema já criado. Embora os namespaces sejam isolados entre si, eles podem ser mapeados para que o contexto principal possa, de alguma maneira saber que existem outros contextos em execução. A Figura 1 demonstra como podem diferentes namespaces podem ser relacionados hierarquicamente.
Figura 1- Arquitetura hierárquica de namespaces.
Para fins de exemplo, suponhamos que os círculos enumerados sejam processos. Na arquitetura hierárquica, os namespaces filhos (Child namespaces) foram originados do namespace pai (Parent namespace), e, com isso, estabeleceu-se uma hierarquia onde, os processos executados pelos filhos são mapeados através de processos no pai. Vale salientar que o identificar nos namespaces filhos são diferentes dos nomeados pelo namespace pai.
A arquitetura não-hierárquica não relaciona os recursos em diferentes contextos. Quanto mais simples for o recurso, mais candidato ele será a utilizar essa arquitetura (UTS, por exemplo). Nessa arquitetura os recursos do namespace filhos não são mapeados para o namespace que o criou (contexto de sistema, por exemplo).
Mas, qual das duas arquiteturas é utilizada atualmente?
Ambas. Dependendo do recurso que está se isolando atráves do namespace, uma ou outra arquitetura é utilizada. E isso pode ser visto em containers LXC e Docker: quando rodamos um processo dentro de um container LXC (um contexto LXC), ele pode ser visto fora do container (no contexto do sistema) pois foi mapeado.
O PID do processo no contexto do lxc será diferente do PID no contexto do sistema. Logo, o PID é um tipo de recurso que utiliza a arquitetura hierárquica em seus namespaces e nos recursos que ele isola.
Conclusão
Namespace é algo incrível, uma feature que alavancou o uso de containers. Existe outra técnina que permite um “isolamento do sistema”, como é o caso do chroot, mas a maneira que ele trabalha é primitiva e não permite integrar com outros elementos de controlo (como o caso do cgroups).
Somente essa pequena explanação já foi capaz de abrir os horizontes e entender como um container funciona e como seus recursos são isolados. Isso responde muitas das dúvidas mais frequentes como: Porque meu pendrive não aparece no meu container? porque minhas regras de firewall não são aplicadas no meu container?
Futuramente, pretendo explanar mais sobre o assunto, mostrando algo mão na massa (Show me code, show me commands!). Qualquer dúvida, ou comentário contrutivo, deixem logo abaixo.
Referências
- Mauerer, W. (2010). Professional Linux kernel architecture. John Wiley & Sons. Capítulo 2.3.2, página 47.
- https://escotilhalivre.wordpress.com/2015/08/12/namespaces/