
Namespaces
Sumário
Antes de começar a discorrer sobre o assunto, gostaria de deixar claro que esse post explicará sobre namespaces de sistema. Mas por quê fiz essa diferenciação? Porque aqueles que programam principalmente em C++ conhecem uma diretiva chamada namespaces que permite o usuário utilizar um escopo diferente em suas variáveis e objetos, evitando assim problemas com nomenclatura idêntica à outros elementos.
O namespace de sistema abrange um pouco da idéia namespace do C++, principalmente a parte de mudança do escopo atual. Em sistemas Unix é comum muitos recursos serem geridos globalmente, por exemplo, o PID (Process ID) é um identificador único gerido globalmente pelo kernel. Nenhum processo possui o mesmo PID. A mesma coisa é válida para dispositivos montados na sua máquina.
A princípio você pode não enxergar nenhum problema na maneira que o sistema controle globalmente alguns recursos, porém vamos pensar no seguinte cenário: Dois clusters (servidores) estão executando processos em um ambiente de computação em nuvem. De repente, uma atividade precisa ser pausada de um servidor e migrada para outro servidor (para aliviar a carga de trabalho de um deles). O que garante que o PID do processo pausado já não esteja sendo utilizado pelo outro servidor? Se esse processo pausado utiliza outros processos, o que garante que os PIDs dos demais processos não estejam sendo utilizados? Na verdade nada.
Podemos até pensar em utilizar uma máquina virtual para executar o processo, pausar e migrar para o outro servidor. Nesse caso o hypervisor garante que não exista conflito, graças a sua isolação. Mas essa abordagem trás consigo uma perda de desempenho e um mal uso dos recursos.
Observando problemas como esse que o namespace foi implementado.
O que é namespace?
Uma feature que permite o sistema criar diversos contextos diferentes em um mesmo sistema, ou seja, permite criar diferentes ambientes independentes que são executados no sistema base.
Com namespace eu consigo isolar um processo do ambiente de outro processo permitindo até mesmo que dois ou mais processos possuam o mesmo PID, porém em ambientes isolados. Permite que um sistema possua múltiplas visões, ou seja, que o sistema seja observado de diversas maneiras diferentes.
É chamado por alguns de virtualização leve, porém não concordo muito com esse termo pois classifico como virtualização um conjunto de atributos a mais que por si só não é oferecido pelo namespace. Os containers utiliza-o para oferecer isolamento (Você pode saber mais sobre containers em dois dos meus posts: aqui e aqui).
namespaces são utilizado em diferentes recursos do sistema. Introduzido em 2002 na versão 2.4.19 do kernel Linux, o mount namespace foi o primeiro recurso a suportar múltiplas visões do mesmo recurso. O user namespace foi o último a ser implementado até o momento (sim, existem diversos recursos que podem possuir namespace), disponível na versão 3.8 do kernel Linux.
Ao total existem 6 recursos que utilizam namespaces:
- mount namespaces (mnt)
- process id namespaces (pid)
- unix timesharing system namespace (uts)
- network namespace (net)
- inter-process comunication namespace (ipc)
- user namespace (usr)
Outros recursos disponíveis nos sistemas Unix podem receber implementações de namespace. O artigo [1] propõe implementar 10 namespaces para gerir todo espaço global existente no Linux. Desses, apenas 4 ainda não são implementados (estuda-se possibilidades de implementação futuramente).
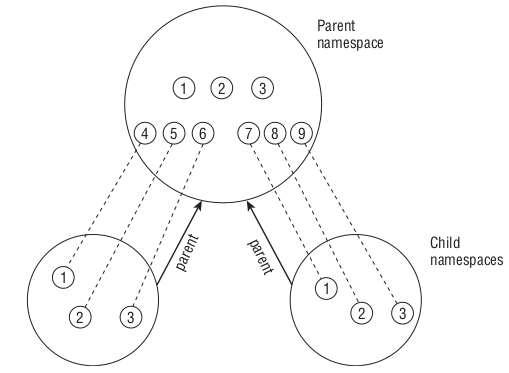
O namespace possui duas arquiteturas: hierárquica e não-hierárquica.
A arquitetura hierárquica é constituída de namespaces pai e filhos. O namespace pai conhece todos os filhos e relaciona os processos executados pelos filhos a um de seus processos. Os filhos não sabem da existência do pai e nem de seus irmãos. Essa arquitetura retira os processos globais dos filhos mas cria novos processos para correlacioná-los. A figura abaixo apresenta a arquitetura hierárquica.
Implementação
A estrutura de dados responsável por permitir o agrupamento do namespace é o nsproxy, definida no arquivo include/linux/nsproxy.h. Abaixo, podemos observar a declaração:
1
2
3
4
5
6
7
8
struct nsproxy {
atomic_t count;
struct uts_namespace *uts_ns;
struct icp_namespace *icp_ns;
struct mnt_namespace *mnt_ns;
struct pid_namespace *pid_ns;
struct net *net_ns;
}
Existem 5 ponteiros para cada namespace com exceção do user namespace. Isso é devido a especialidade da implementação do user namespace. Todos as demais estruturas de namespace (*namespace) possui um ponteiro para user namespace denominado user_ns.
A principal razão de separar o user namespace da estrutura nsproxy é devido a diferenças de permissões de segurança que são implementado através de capacidades (capability). A estrutura nsproxy precisa de uma capability denominada CAP_SYS_ADMIN (generalizando, é uma permissão parecida com o sudo) enquanto que o user namespace faz parte de um grupo de estruturas de credenciamento chamado cred que representa um contexto de segurança diferente de um processo. Nesse momento você pode se perguntar:
Apesar de um pouco complicado pude entender como a estrutura nsproxy, mas como um programa é capaz de indicar a qual namespace ele pertence?
Isso é mais simples do que a explicação da implementação do namespace. O kernel representa cada processo executado no computador através de uma estrutura de dados denominado task_struct. Essa estrutura representa um descritor de processos e sua função é associar um programa em execução a uma série de regras regidas por essas estrutura.
Sabendo disso, a estrutura task_struct contém, como um de seus atributos, uma referência da estrutura nsproxy. Usar a estrutura nsproxy ao invés de suas 6 variáveis soltas em task_strut é simplesmente para fins de otimização.
Clone flags
São váriáveis utilizadas para indicar as chamadas de sistema (system calls) qual namespace deve ser criado. Ao total são 6 e são definidas no arquivo include/linux/sched.h
- CLONE_NEWNS: mount namespace
- CLONE_NEWUTS: unix timesharing system namespace
- CLONE_NEWIPC: inter-process call namespace
- CLONE_NEWPID: process id namespace
- CLONE_NEWNET: network namespace
- CLONE_NEWUSER: user namespace
Como veremos a seguir, as system calls utilizadas pelos processos foram adaptadas para suprir as dependências dos namespaces, adicionando as clone flags para indicar qual atividade deve ser realizada naquela system call.
System calls
Com a implementação dos namespaces algumas system calls tiveram seu comportamento adaptado (como é o caso do clone(), fork()). Foi necessário também criar mais duas system calls: unshare() e setns()
unshare()
Responsável por criar o objeto nsproxy e adicioná-lo ao processo que chama a system call. As clone flags passadas por parâmetro indica qual o tipo de namespaces que será criada. Uma exceção é quando a clone flag CLONE_NEW_PID é passada como parâmetro. Nesse caso, unshare() redireciona a chamada para outra system call, a fork().
A implementação de unshare() pode ser conferida em kernel/fork.c.
setns()
Adiciona o processo que chama a system call a um namespace existente. Diferentemente de unshare(), a existência do namespace é necessário (caso contrário a chamada retorna um erro). A assinatura do método recebe dois parâmetros:
1
setns(int fd, int nstype)
Onde:
- fd (file descriptor): Um descritor que refere-se a um namespace. O descritor é localizado no diretório /proc/
/ns/ - nstype : Especifica através de uma clone flag qual o tipo do namespace. Esse parâmetro é opcional.
- Se o valor for 0, o valor de fd pode ser qualquer um
- Se o tipo especificado por nstype for diferente do tipo determinado por fd, ocorre o erro -EINVAL
A implementação de setns() encontra-se em kernel/nsproxy.c
Conclusão
O conteúdo apresentado aqui foi baseado em uma apresentação de minha autoria a um grupo do mestrado e encontra-se abaixo.

Das features implementadas ultimamente no kernel o namespace e o cgroups são, sem dúvidas, aquelas que mais chamaram atenção pela originalidade e pela gama de opções abertas. Essas duas features são o alicerce de aplicações como LXC, OpenVZ e CRIU (Check/Restore in Userspace).
Embora o post seja mais voltado ao entendimento da implementação, futuramente mostrarei um uso prático para observar-mos como pode ser utilizado para fins administrativos.
Referências
[1] Biederman, E. W., & Networx, L. (2006, July). Multiple instances of the global linux namespaces. In Proceedings of the Linux Symposium.
[2] Rosen, R. (2013). Linux Kernel Networking: Implementation and Theory. Apress.
[3] Mauerer, W. (2010). Professional Linux kernel architecture. John Wiley & Sons.